
Artykuł omawia pakiet programów służący do syntezy mowy w oparciu o nagraną bazę głosową dla dowolnego języka.
Pełen tekst w formacie PDF.
Wprowadzenie
Geneza
W niniejszej pracy została poruszona tematyka zamiany języka pisanego na mowę. Transformacja tekstu na mowę nosi nazwę ”Synteza mowy”. Proces syntezy polega na otrzymaniu produktu będącego związkiem bardziej skomplikowanym niż substraty, od jakich pochodzi. W algorytmie dokonującym zamiany tekstu na mowę (TTS – Text To Speech) produktem syntezy jest mowa. Natomiast substratami są; tekst, alfabet, fonemy, baza sampli oraz relacje. Syntezatory mowy znajdują coraz szerszy krąg zastosowań. Komunikacja głosowa maszyny z człowiekiem jest obecnie coraz bardziej rozpowszechniona. Budowane są systemy ”Call Center”, które informują użytkowników o bieżącym stanie kont bankowych, udzielają informacji o aktualnym stanie pogody, lub ułatwiają zdalne wykonywanie operacji bankowych (doładowywania kont i tym podobne). System ”Call Center” jest dostępny przez całą dobę w każdym dniu tygodnia. Jest to możliwe dzięki zastosowaniu maszyn, które odczytują tekst i rozpoznają wprowadzane informacje. Między innymi dzięki syntezatorom, systemy te stają się tanie w utrzymaniu. Syntezatory pomagają osobą niepełnosprawnym (w szczególności niewidomym). Umożliwiają łatwiejszy dostęp do wielu informacji, jak np. strony internetowe (programy screen reader) lub książki w formie elektronicznej. Dzięki omawianym tu rozwiązaniom również i wypoczynek staje się przyjemniejszy. Oglądanie filmów z napisami jest dla wielu osób uciążliwe (np. dzieci), zaimplementowany syntezator mowy wykonuje dubbing. Komunikaty głosowe wykorzystywane są w nawigacji satelitarnej, ułatwiając kierowanie pojazdami. Wydawane polecenia głosowe umożliwiają szybszą reakcję kierowcy nie odwracając przy tym jego uwagi od sytuacji na drodze. Rozwijającym się kierunkiem, w jakim ma szanse zaistnieć synteza mowy jest cybernetyka i robotyka.
Cele
Celem niniejszej pracy inżynierskiej jest stworzenie narzędzi lingwistycznych. Za pomocą zdefiniowanych procedur opartych na algorytmach ”Text To Speech”, oraz konkatencyjnym wykonujących operację zamiany definiowalnych zbiorów znakowych na komplementarne odpowiedniki werbalne.
Teza
Niniejszy zbiór podprogramów lingwistycznych, informatycznie zespolonych w moduł komplementarny, realizuje zadania związane z analizą tekstu pisanego, gdzie treść pisemnej wypowiedzi cyfrowej podlega ewaluacji (ocenie) syntaktycznej. Sukcesywnie zostaje ona przetransformowana w adekwatny zbiór dźwięków reprezentujących pierwotny zbiór treści pisanej. Napotkane struktury językowe podczas analizy, zapisane w bazie przydzielonej aktualnie rozpatrywanemu językowi, zostają poddawane transkrypcji. Język może zostać wykreowany na podstawie tekstu źródłowego i po operacjach diagnostycznych, samplowaniu, strukturyzacji jest używany przez stały algorytm TTS (”Text To Speech”). Możliwa jest również walidacja oraz korekta utworzonej bazy językowej.
I. Analiza rozwiązań
I.1 Analiza istniejących rozwiązań
W tym punkcie zostanie przedstawiona analiza istniejących rozwiązań problemu syntezy mowy. Przybliżone zostaną także ogólne informacje dotyczące tego procesu, stosowane algorytmy syntezy oraz istniejące rozwiązania programowe.
”Proces syntezy mowy dzielimy na dwa etapy. W pierwszym z nich program wydobywa z wprowadzonej frazy jak największą ilość informacji lingwistycznych – stara się zrozumieć tekst. Etap ten nazywany jest przetwarzaniem języka naturalnego NLP (ang. Natural Language Processing). Później następuje utworzenie dźwiękowej wypowiedzi frazy na podstawie zdobytych o niej informacji – jest to etap cyfrowego przetwarzania sygnału DSP (ang. Digital Signal Processing). W obu wyżej wymienionych etapach jest wykonywanych wiele pośrednich kroków, wymagających sporej wiedzy lingwistycznej i matematycznej.
Pierwsze próby syntezy głosu, pochodzą z roku 1773. Badania w owym czasie prowadził Ch. G. Kratzenstein, który posiadał tytuł profesora fizjologii na uniwersytecie w Kopenhadze. Wiedza z anatomii oraz zainteresowanie instrumentami muzycznymi, doprowadziły do zbudowania niezwykłych organów, jakie generowały dźwięki samogłoskowe. lang=DE style=’mso-ansi-language:DE’>Dokładny opis budowy tego urządzenia można znaleść w ”Mechanismus der menschlichen sprache nebst beschreibung einer sprechenden maschine” autorstwa Wolfganga von Kempelena (1791). Urządzenie doczekało się zrekonstruowania w roku 1835 i instalacji w Dublinie. Kolejne osiągnięcia należą do Josepha Fabra (1846-Londyn), który zbudował śpiewającą maszynę nazwaną ”Euphonia”, oraz R.R.Riesz (1937-USA), którego urządzenie wiernie odwzorowywało mowę. Homer Dudley, w czasach, gdy znana już była elektryczność zaprezentował urządzenie oparte właśnie na niej. Ochrzczono je imieniem ”Voder” i zaprezentowano w Nowym Jorku 1939 roku. Natomiast 1950 rok należał do Frank’a Cooper’a, urządzenie skanowało tekst wiązką światła a następnie go odczytywało. Od roku 1970 nastąpiło trwałe związanie syntezy mowy z komputerami. Obecnie prowadzi się wiele bardzo zaawansowanych prac nad udoskonaleniem syntezatorów, ich głosy nie są już bezosobowe. Można określać wiek, płeć a czasem i emocje w głosie, podczas odczytu tekstu przez maszynę.
Jedną ze starszych metod (początek epoki komputerów) jest formantowa synteza głosu. Polega ona na modulacji częstotliwością sygnału, tak by otrzymać jak najbardziej podobny dźwięk do formantów głosek. Otrzymywane efekty nie są jednak zadowalające.
Późniejszym algorytmem syntezy mowy, jest metoda artykulacyjna. Jej działanie oparte jest o budowę ludzkiego aparatu mowy. By wygenerować głoskę potrzebne jest około sześćdziesięciu parametrów. Ten rodzaj syntezy jest w zasadzie tylko teoretyczny i nie jest rozpowszechniony.
Zakładając, że uzyskany dźwięk ma być jak najbardziej zbliżony do ludzkiego głosu, najprostszym rozwiązaniem jest zastosowanie jego próbek (tak zwanych sampli, lub segmentów). ”Metoda konkatencyjna polega na nagraniu dużej bazy prawdziwego głosu lektora (tzw. Baza segmentów), jej oznaczeniu i przetworzeniu, a następnie w procesie syntezy mowy wybieraniu, modyfikowaniu oraz składaniu sygnału mowy z fragmentów wcześniejszych nagrań. Technika ta pozwala na uzyskanie mowy najbardziej naturalnej.”
Procesy zachodzące w poszczególnych etapach syntezy mowy zostały wyszczególnione poniżej.
W etapie NLP wyróżniamy następujące działania:
- analiza tekstu,
- transkrypcja fonetyczna,
- generowanie prozodii,
- wysłanie danych do DSP.
Natomiast w etapie DSP zachodzą takie procesy jak:
- odbiór fonemów i prozodii z etapu NLP,
- dekodowanie / dekompresja segmentów (dzięki bazie segmentów),
- dopasowanie prozodii,
- konkatenacja, czyli łączenie segmentów,
- synteza sygnału,
- mowa.
I.2 Koncepcja rozwiązania
”W toku ewolucji, przez setki tysięcy lat, natura wytworzyła jeden z najdoskonalszych systemów służących do komunikacji – mowę. Istnieje wiele języków i dialektów, jednakże aparat mowy w każdym przypadku jest ten sam. Powstające za jego pomocą dźwięki niosą odbiorcy całe mnóstwo informacji. Oprócz tych związanych z treścią – tzw. semantycznych, są także osobnicze, pozwalające na rozpoznanie osoby mówiącej, oraz emocjonalne, pozwalające odgadnąć stan osoby mówiącej, jak na przykład jej zdenerwowanie, wzruszenie, rozbawienie, a także całe mnóstwo innych informacji takich jak status społeczny, wykształcenie, pochodzenie, a nawet stan zdrowia. Wszystko to jest możliwe za sprawą procesu artykulacji, czyli kształtowania dźwięków mowy ludzkiej, oraz percepcji. Natura doprowadziła je do perfekcji. Są one bardzo złożone, towarzyszą im także inne procesy, nie mniej skomplikowane, przez co angażują one ogromne zasoby mózgu ludzkiego. Co ciekawe, znakomita większość z nich zachodzi jednak bez udziału świadomości, są dla nas „automatyczne”, naturalne. Cała doskonałość tego systemu powoduje wrażenie, iż mowa, a nawet cały proces porozumiewania się, zdaje się być prosty, łatwy, wręcz banalny. Jednakże bardziej wnikliwe obserwacje tych zjawisk, a przede wszystkim próby odtworzenia i wykorzystania ich w świecie techniki, ukazują nam stopień komplikacji tego procesu.”
Na podstawie wniosków, wyciągniętych w trakcie testowania własnego algorytmu o założeniach zbliżonych do algorytmu konkatencyjnego (wzbogaconego w analizę struktur językowych) została opracowana koncepcja rozwiązania. Istotną różnicą między przedstawionym tu rozwiązaniem, a już istniejącymi jest liczba definiowalnych języków. Syntezatory mowy TTS dostępne na rynku mają wbudowaną strukturę budowy języka w kod programu – oznacza to, że nie można ingerować w raz zaprogramowane zasady odczytu tekstu. Przedstawiony w niniejszej pracy pakiet programów nazwanych ”SYNT” zawiera syntezator mowy (TTS). Posiada także aplikacje umożliwiające zdefiniowanie zasad odczytu tekstu w definiowanym języku, na podstawie przykładowego tekstu źródłowego i zapisanych struktur językowych. Jest to nowe rozwiązanie o znacznie większej złożoności od obsługi raz ustalonego języka w momencie kompilacji syntezatora.
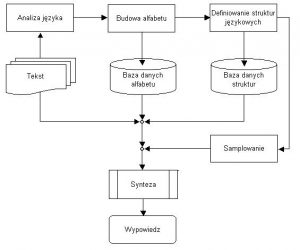
Rys. 1.2.1 Schemat procesów transformacji języka z formy pisemnej na werbalną
Na Rys.1.2.1 został przedstawiony proces powstawania wypowiedzi werbalnej na podstawie tekstu pisanego. Podstawowymi procesami są; analiza języka oraz budowa alfabetu. Alfabet jest tworzony po wykonaniu analizy tekstu o odpowiedniej ilości znaków. Dłuższy tekst wykazuje lepsze wyniki analizy od tekstu krótkiego. Związane jest to z tym, że przy dłuższej kombinacji znaków występuje większe prawdopodobieństwo powstania powiązań językowych, oraz użycia symboli znakowych, niż w tekście krótkim. W wielu językach alfabet posiada znaczną ilość znaków oraz fonemów. Do ich całkowitego poznania konieczne jest wprowadzenie większej ilości tekstu (minimum kilka stron). Jeśli mają być dodatkowo analizowane cechy fonologiczne relewantne (dźwięczność lub ubezdźwięcznienie) oraz generowanie prozodii (akcent, intonacja, iloczas), wtedy algorytm jest wysoce skomplikowaną analizą struktur.
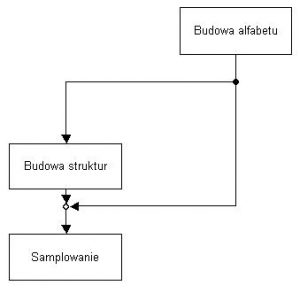
Rys. 1.2.2 Relacja między modułami analizującymi budowę języka
Proces budowy języka został podzielony na moduły, przypisane poszczególnym aplikacjom o wspólnej nazwie pakiet ”SYNT”. Wszystkie aplikacje połączone razem rozpoznają budowę języka, jaki jest używany przez syntezator mowy. Mogą one działać oddzielnie, pozwalając na edycję poszczególnych elementów tworzących język. Schemat ogólnych oddziaływań między modułami podczas rozpoznawania języka przedstawia Rys. 1.2.2
System składa się z trzech modułów rozpoznających budowę języka, oraz syntezatora mowy, oznacza to potrzebę stworzenia czterech programów, które współdzielą ze sobą bazy danych zapisane na dysku twardym. Rozmieszczenie poszczególnych katalogów zawierających dane dla aplikacji (przedstawione na Rys.1.2.3), zostało zaplanowane tak, by stało się czytelne zarówno dla maszyny jak i użytkownika. W folderze głównym znajdują się programy wykonywalne, są to; ”Syntezator”, ”Sampler”, ”Kreator” oraz ”Strukturyzator”. Został w nim także utworzony folder z danymi potrzebnymi do działania wymienionych programów, zawierający pliki graficzne oraz pliki wymiany. Ważnym katalogiem jest katalog ”sample”. Zostały w nim umieszczone kolejno: ”baza.txt” (spis wszystkich baz językowych), oraz (jeśli istnieją bazy językowe) pliki z rozszerzeniem *.synt i katalogi o tych samych nazwach. Wewnętrzna budowa pliku *.synt oparta jest na standardach plików informacyjnych *.ini systemu Windows™. Pliki w tym katalogu należy wskazać syntezatorowi w trakcie wyboru bazy językowej, podczas którego syntezator pozwala jedynie na wybór plików o rozszerzeniu *.synt. Zawiera on informacje konfigurujące syntezator oraz wskazuje miejsce, w jakim przechowywane są sample (katalog o tej samej nazwie, co plik *.synt) i baza struktur. Ponadto zapisano w nim między innymi czas trwania przerwy pomiędzy poszczególnymi wyrazami, a także przerwy pomiędzy kolejnymi próbkami dźwięków (podawane w mili sekundach). Poniżej znajduję się budowa przykładowego pliku o nazwie ”fonemy_pl.synt”.
Katalog o tej samej nazwie, co plik *.synt przedstawiony na Rys. 1.2.3 zawiera próbki językowe (sample) zapisane w formacie plików dźwiękowych o rozszerzeniu *.wav. Nazwa pliku zawierającego próbkę dźwiękową jest komplementarna z jego odpowiednikiem znakowym. W tym samym katalogu umieszczono ”index.txt”. Zawiera on spis wszystkich nagranych sampli, które znajdują się w bazie, oraz plik ”do_nagrania.txt” posiadający informacje dla programu ”Sampler”, które z wzorców znakowych oczekują jeszcze na przypisanie im odpowiednika dźwiękowego. Plik ten będzie wypełniony danymi zaraz po zakończeniu pracy w programie ”Kreator”. Jego zawartość będzie się zmniejszać wprost proporcjonalnie do tego jak zwiększać się będzie rozmiar pliku ”index.txt” w trakcie działania programu ”Sampler”. W chwili, gdy wszystkie wzorce znakowe będą posiadały swoje dźwiękowe odpowiedniki plik ”do_nagrania.txt” będzie pusty, a jego zawartość zostanie przepisana do ”index.txt”. W przypadku usunięcia sampli (funkcja dostępna w programie ”Sampler”), przepływ danych będzie zwrócony w odwrotnym kierunku. Wzorce znakowe oczekujące na przypisanie im odpowiedników dźwiękowych można trwale usuwać lub dodawać ( w programie ”Sampler”). Kolejnym plikiem znajdującym się w omawianym katalogu są ”struktury.dat”, zawierający dane zgodne ze standardem zapisu danych w systemie Windows™. Informacje (przedstawiające struktury powiązań językowych) zapisane w tym formacie nie mogą podlegać edycji w innych programach, niż te z pakietu ”SYNT”.
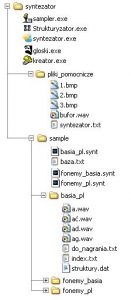
Rys. 1.2.3 Rozmieszczenie na dysku danych i programów pakietu ”SYNT”.
Struktury są skróconym zapisem znakowym, jaki może zostać zapisany znakowo w sposób rozwinięty. Obydwa zapisy posiadają taki sam odpowiednik werbalny. Struktury można podzielić pod względem ich złożoności.
Wybrane struktury proste:
– Podstawowe znaki, z jakich zbudowany jest alfabet np. ”A”,”b”,
– skróty językowe np. ”m.n.p.m”, ”itp.”,
– cyfry od zera do granicy ich powtarzalności (do przyrostka ”naście”) i niektóre cyfry rozpoczynające kolejne jednostki rzędu decy ”dwadzieścia”, ”pięćdziesiąt”, ”sto”.
Wybrane struktury złożone:
– Cyfry od granicy ich powtarzalności (od przyrostka ”naście”),
– uproszczenia językowe np. ”isn’t” oznaczające ”is not”.
Często struktury proste stanowią element budowy zarówno struktur prostych jak i złożonych. Struktury proste posiadają przypisane odpowiedniki dźwiękowe, natomiast złożone zostają zdefiniowane za pomocą struktur prostych.
W przypadku numeru 130, należy stworzyć strukturę złożoną. W skład przedstawionej cyfry wchodzą struktury proste: ”1”, ”3” i ”0”, które posiadają odpowiednik werbalny brzmiący ”jeden”, ”trzy”, ”zero”. Jednak z uwagi na ich rozmieszczenie względem siebie, ich odpowiednikami struktur prostych będą ”100”, ”30”, ”NULL”, natomiast ich werbalne odpowiedniki to ”sto”, ”trzydzieści”, ””
| 1 | 3 | 0 |
| Przedrostek (prefiks) | Wrostek (infiks) | Przyrostek (sufiks) |
Strukturę złożoną można opisać przestrzennie. Zgodnie z przedstawionym przykładem liczba
”3” jest infiksem, ”1” prefiksem natomiast ”0” sufiksem. Z uwagi na to, że strukturami złożonymi nie są tylko liczby, algorytm nie opiera się na sprawdzaniu rzędu jedności, dziesiątek, setek i wyższych rzędów. Po wprowadzeniu tekst zostaje on umieszczony w tablicy, w której znaki następują kolejno po sobie. Analizę można rozpocząć po uprzednim zdefiniowaniu budowy struktury. Rys.1.2.4. W skład struktury wchodzi ”hasło”, ”maska” i ”efektor”, natomiast maska zawiera definicję czy występuje ona ”przed” czy ”po” ”haśle” Rys. 1.2.4.
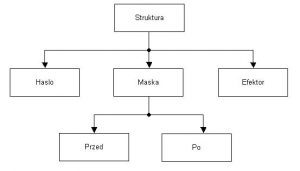
Rys. 1.2.4 Budowa struktury
Przykład z Rys. 1.2.5 pokazuje strukturę złożoną ”21”, która została umieszczona w tablicy statycznej N zakończonej w N[8] a rozpoczynającej się w N[1], struktura zajmuje pozycje od N[5] do N[6]. Algorytm analizujący struktury przegląda tablicę od jej początku aż do końca.
| E | L | A | 2 | 1 |
Rys. 1.2.5 Tablica statyczna N wypełniona przykładowym tekstem
W przypadku napotkania struktury (znaku) sprawdzane jest czy spełnia ona warunki struktury złożonej. Sprawdzona zostaje zgodność elementu tablicy z hasłem struktury, w przypadku jej stwierdzenia analizowana jest maska. Maska definiuje ile znaków (struktur prostych) może występować po haśle. Gdy zależność ta nie zwraca negacji, sygnalizuje to wykrycie struktury złożonej. Jej efektor zostaje wpisany od miejsca jej wykrycia a rozmiar tablicy statycznej jest zmieniany na nowy, powiększony o długość ”efektora”. Przykład z Rys. 1.2.5 przedstawia definicje struktur zamieniających ”21” na ”dwadzieścia” ”jeden” jest ona zrealizowana w sposób przedstawiony poniżej:
Struktura złożona ”dwadzieścia”:
Przed=false (maska nie występuje przed hasłem)
Po=true (maska występuje po haśle)
Maska: # (co oznacza jeden dowolny znak)
Hasło: 2 (po napotkaniu tego znaku analizowana jest struktura złożona)
Efektor: ”dwadzieścia” (zakończony spacją)
Struktura prosta ”jeden”:
Przed=false (ponieważ brak maski)
Po=false (ponieważ brak maski)
Maska: NULL (brak)
Hasło: 1 (po napotkaniu tego znaku zamieniany jest on na efektor)
Efektor: ”jeden” (zakończony spacją)
Struktury operują morfemami, analizują prefiksy, sufiksy i interfiksy na tablicach znaków, gdzie pojedynczy element tablicy zawiera dokładnie jedną strukturę prostą, jaka w relacji z otaczającymi ją innymi strukturami prostymi może tworzyć strukturę złożoną.
Algorytm powstawania mowy, oparty na metodzie konkatencyjnej został przedstawiony na Rys.1.2.1. Do przeprowadzenia procesu syntezy TTS potrzebne są następujące substraty: ”Baza danych sampli”, ”Baza danych struktur”, ”Baza danych alfabetu” oraz tekst w zdefiniowanym języku. Z substratów zostaje otrzymany produkt – mowa Rys. 1.2.6. Proces syntezy odbywa się etapowo. Niemożliwe jest powiązanie wszystkich elementów podczas trwania jednego kroku, ponieważ zakłóci to działanie całego procesu. Analiza struktur Rys. 1.2.7 operuje na znakach, a jako produkt otrzymuje się znaki Rys.1.2.6. W kolejnym etapie na przetransformowanym tekście poczynione zostaje przypisywanie próbek dźwiękowych do ich znakowych odpowiedników, efektem jest werbalizacja Rys.1.2.8.
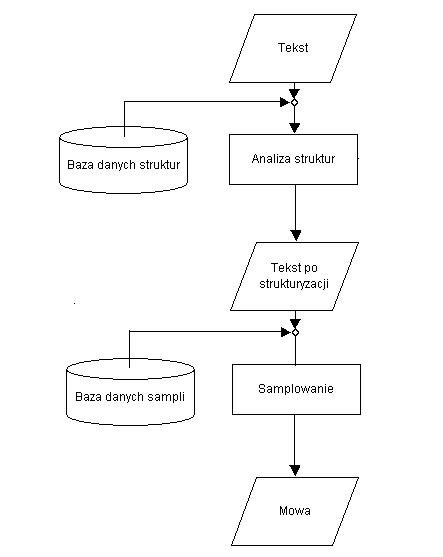
Rys. 1.2.6 Ogólny schemat opracowanego algorytmu TTS
Analizę struktur przedstawia Rys. 1.2.7. Operuje ona na bazie, która zawiera pojedyncze struktury. Budowę pojedynczej struktury przedstawia Rys. 1.2.4. Algorytm Rys. 1.2.7 sprawdza ilość posiadanych w bazie rekordów, pod kątem każdego z nich analizuje wprowadzony tekst. Po pobraniu z bazy jednej struktury, analizowane są kolejne znaki tekstu do chwili napotkania ostatniego znaku. Kolejne znaki poddawane są komparacji z ”hasłem” struktury i w przypadku wystąpienia ciągu we wprowadzonym tekście, jaki odpowiada na ”hasło” wykonywana jest dokładna analiza. Zostają sprawdzone maski struktury za pomocą wirtualnej injekcji analitycznej (przestrzenne potwierdzenie istnienia maski i hasła w tekście). Po otrzymaniu informacji potwierdzającej obecność zdefiniowanej ”maski” w miejscu analizowanego tekstu wstawiany jest ”efektor”. Po dokonaniu rozpoznania struktury lub wykazania jej braku, algorytm przechodzi do kolejnego znaku tekstu, jaki nie został jeszcze przeanalizowany. W chwili, gdy tablica znaków wprowadzonego tekstu zostanie cała przeanalizowana, algorytm pobiera kolejną strukturę z bazy i proces powtarza się do momentu sprawdzenia tekstu z udziałem wszystkich struktur z bazy. Analizowany tekst jest tablicą statyczną w trakcie trwania analizy, nowa tablica powstaje po rozpoznaniu struktury i wpisaniu zawartości poprzedniej tablicy, oraz ”efektora” struktury. Zmienność tekstu wymaga ciągłego sprawdzania wielkości tablicy. Zasada ta uniemożliwia analizowanie wszystkich struktur w jednym kroku. Po wykonaniu algorytmu, tekst zawiera struktury proste, jakie posiadają odpowiedniki dźwiękowe. Kolejnym etapem jest transformacja TTS.
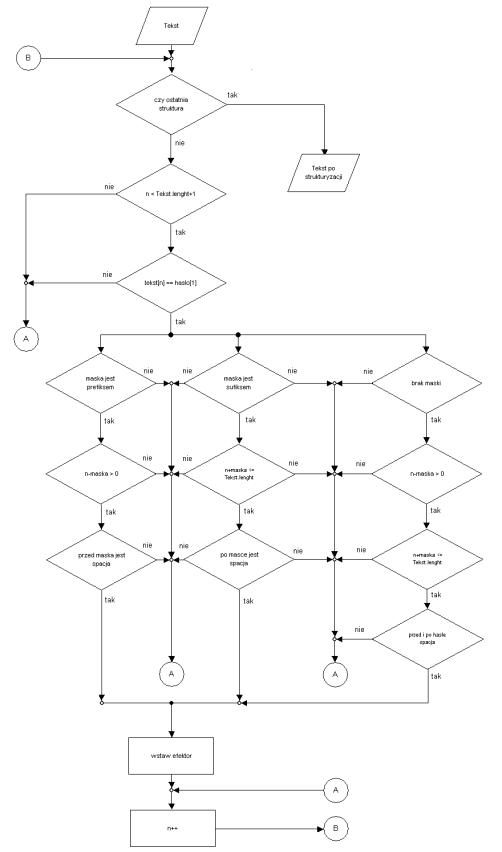
Rys. 1.2.7 Schemat procesu analizy struktur
Proces przypisywania sampli, nazywany ”Text To Speech” przedstawia Rys. 1.2.8. Czas procesora jest zajmowany przez algorytm TTS krócej niż przez algorytm analizy struktur. Wykonywanych zostaję mniej analiz i pętli, mniejsze jest też użycie baz danych. Algorytm otrzymuje jako substrat tekst po strukturyzacji (lub tekst zwykły w przypadku, gdy analiza struktur nie została wykonana). Po ustawieniu karety (pozycja odczytu) na początek tekstu, zostaje on sprawdzony, czy zawiera znaki. W przypadku, gdy ich nie posiada algorytm zostaje zatrzymany. Wartość zmiennej ”kareta” przepisywana zostaje do zmiennej ”n”. Zmienna ”bufor” jest to ciąg pomocniczy, w którym przechowywany jest analizowany tekst podczas jednej operacji przeszukiwania. Natomiast ”sampl” to zmienna ze znalezionym najdłuższym buforem, posiadającym odpowiednik w bazie sampli. Zmienne ”bufor” oraz ”sampl” są zerowane. Pobierany zostaje ”n-ty” element tablicy tekstu. Jeśli nie jest spacją oznacza, że rozpoczyna się wyraz i poszukuje się najdłuższego możliwego wzorca dźwiękowego. Operacja polega na wykonywaniu pętli aż do napotkania kolejnej spacji – końca wyrazu. Pętla wykonuje się od pozycji karety równej ”n” do pozycji ”n+x” gdzie ”x” oznacza pozycję kolejnej spacji. Sprawdzane zostają wartości granic tablicy tekstu. Bufor uzupełnia się o kolejny znak analizowanej tablicy tekstu. Gdy zawartość znakowa bufora znajdzie swoje odzwierciedlenie w bazie sampli, do zmiennej ”sampl” przypisywana jest wartość bufora. ”Kareta” znajduje się w aktualnej pozycji ”n”. Poszukiwanie ”sampla” odbywa się od początku. Pobierany jest kolejny znak i zostaje sprawdzone czy dłuższa kombinacja znajdzie odzwierciedlenie w bazie sampli. Zadaniem algorytmu jest znalezienie możliwie najdłuższego ciągu znaków, jaki posiada odpowiednik w bazie sampli (komplementarność). Algorytm samplowania w początkowej wersji posługiwał się znaną długością sampli (na przykład samplowanie po jednym znaku, lub po dwa). Na obecnym etapie rozwoju poszukuje najlepszych rozwiązań.
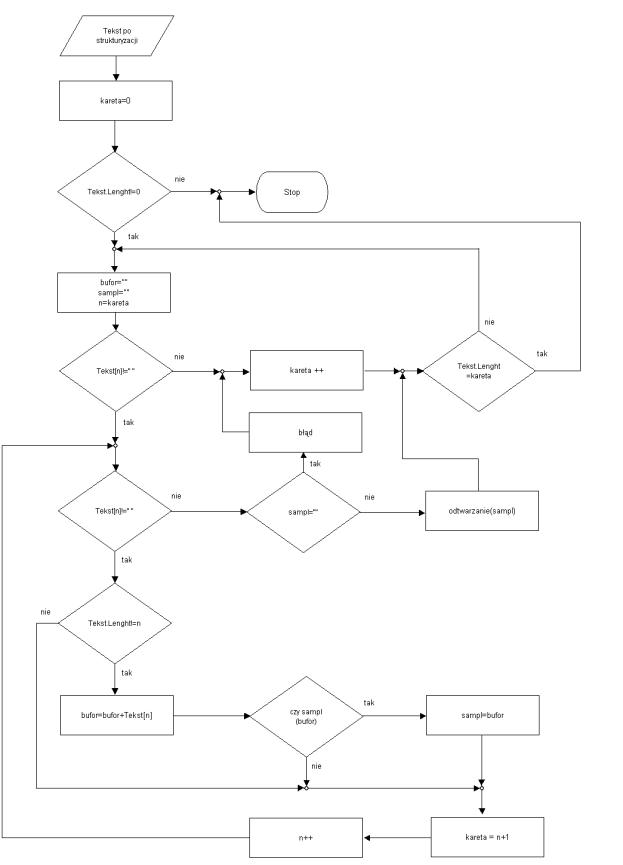
Rys. 1.2.8 Schemat procesu Samplowania – powstawanie mowy
II. Opis funkcjonowania programu
Algorytmy omawiające problematykę rozdziału [1.2] zostały zaprogramowane w ”C++ Builder”, powstały zbiór aplikacji nazwano ”SYNT”. Został on wyposażony w narzędzia, opisane w rozdziale [1.2]. Na Rys.1.2.2 przedstawiono relacje pomiędzy modułami analizującymi budowę języka, w tej kolejności zostaną przedstawione aplikacje, ich obsługa, oraz fragmenty kodu.
II.1 Kreator
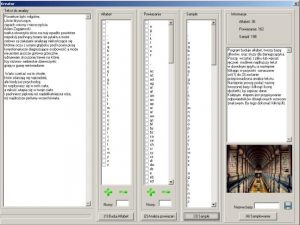
Rys. 2.1.1 ”Kreator” do analizy języka, program pakietu ”SYNT”
Pierwszym programem pakietu ”SYNT” jest ”Kreator”. Praca w z nim rozpoczyna się od wpisania lub wczytania możliwie jak najdłuższego tekstu w analizowanym języku, jest on widoczny w polu ”Tekst do analizy”. Zadaniem aplikacji jest przeprowadzenie tekstu przez szereg filtrów językowych, jakie tworzą alfabet, a następnie analizują proste powiązania językowe, jak np. ”rz” ”cz” (tworzenie difonów). Ostatni filtr buduje listę znaków, którym zostanie przypisany wzorzec dźwiękowy. W programie istnieje możliwość zdefiniowania struktur językowych (jednak nie jest konieczna na tym etapie analizy i można je uzupełnić w programie ”Strukturyzator”).

Rys. 2.1.2 Obiekty klasy TcheckListBox
Pierwszy filtr tworzący alfabet uruchamiany zostaje po naciśnięciu przycisku ”(1) Buduj Alfabet”. W komponencie klasy TcheckListBox zostaje wyświetlony rezultat. Istotną sprawą jest by usunąć wszystkie nieodpowiednie znaki nie należące do alfabetu. Można tego dokonać zaznaczając je na liście i klikając w ”zielony minus”. Lub dodać brakujące, po wpisaniu znaku w polu ”nowy” i klikając w ”zielony plus” Rys. 2.1.2. ”(2) Analiza powiązań” uruchamia filtr powiązań. Powstałe elementy zostają również wyświetlone w TcheckListBox i podobnie jak w przypadku alfabetu można dodawać nowe oraz usuwać już istniejące Rys. 2.1.2. ”(3) Sample”, jest to ostatni filtr tworzący listę sampli. Efekt wyświetla się w komponencie TlistBox Rys. 2.1.2. Użytkownik nie ma możliwości edycji powstałej listy.
Kod w języku C++ pobierający alfabet z tekstu przedstawia ”załącznik 1”, analiza powiązań została rozwiązana w sposób przedstawiony w ”załączniku 2”. Funkcje jakie zostały użyte we wspomnianych algorytmach zawiera ”załącznik 3”.
Po zakończeniu rozpoznania budowy języka, gdy wykonano analizę tekstu przy użyciu wszystkich filtrów językowych od (1) do (3) pokazanych na Rys. 2.1.2, należy zapisać projekt jako nową bazę językową. Nazwę bazy podaje się w polu Tedit, a następnie w celu jej zapisania należy nacisnąć ikonę dyskietki Rys. 2.1.3. Kolejny etap to przypisywanie wzorców dźwiękowych do stworzonych wzorców znakowych. Przejście do aplikacji samplującej nastąpi po kliknięciu w przycisk ”(4) Samplowanie”.
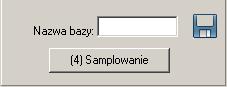
Rys. 2.1.3 Utworzenie bazy językowej
II.2 Sampler
Zadaniem programu ”Sampler” jest nagranie próbek (wzorców) językowych i przypisanie ich odpowiednikom znakowym, które zostały stworzone w programie ”Kreator”. Próbki są zapisane jako baza językowa, która umożliwia odczyt języka przez syntezator. Baza sampli może być nagrywana, edytowana oraz usuwana w programie ”Sampler”. Istnieje również możliwość dodania nowych sampli, gdy ich potrzeba zostanie wykazana w trakcie pracy aplikacji ”Syntezator”. Obsługa procesu przypisywania próbek dźwiękowych do ich odpowiedników znakowych przeprowadzana jest przez użytkownika. W panelu ”bazy językowe” przedstawionym na Rys. 2.2 widoczne są aktualnie dostępne języki, które mogą być analizowane przez ”Syntezator”. Zielony ikona ”plus” umożliwia dodanie nowych baz językowych(uruchamia program ”Kreator”), natomiast ikona ”minus” usuwa wybraną bazę. Dział ”lista sampli do nagrania” zawiera sample, które wymagają przypisania odpowiednika dźwiękowego. Sample mogą zostać usunięte z listy po ich podświetleniu i kliknięciu w ikonę ”minus”.
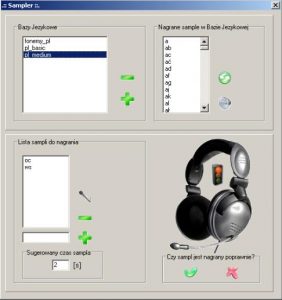
Rys. 2.2 Program ”Sampler” z pakietu”SYNT” do nagrywania i edycji sampli
Natomiast dodanie nowego wzorca znakowego następuje po jego wprowadzeniu z klawiatury (pole obok ikony ”plus”) i kliknięciu w ikonę ”plus”. Przypisanie odpowiednika dźwiękowego wykonywane jest po podświetleniu wybranego wzorca znakowego. Czas trwania nagrania zostaje analizowany przez program, istnieje możliwość jego zmiany w panelu ”sugerowany czas sampla”. Jednostką miary jest sekunda. Gdy zaistnieje konieczność jego korekty, należy to zrobić przed rozpoczęciem nagrywania. Nagrywanie wzorca dźwiękowego rozpoczyna się po naciśnięciu ikony ”mikrofonu”. W prawej części okna przedstawionym na Rys. 2.2 znajduje się obraz słuchawek a w nim ”światła sygnalizacyjne”. Zapalają się one kolejno w kolorach; czerwonym, żółtym (przygotowanie do nagrywania), zielonym (nagrywanie). Zaraz po rozpoczęciu nagrywania należy wymówić do mikrofonu dźwięk reprezentujący głosowy odpowiednik wybranego wzorca znakowego. Po zakończeniu procesu nagrywania jest on odtwarzany. Jeśli został zarejestrowany poprawnie, potwierdza się to kliknięciem w zieloną ikonę ”Tak”, w przypadku nieprawidłowego samplowania program informuje się o tym klikając czerwoną ikonę ”Nie”. Poprawnie nagrany dźwięk na podstawie wzorca znakowego staje się samplem, który jest używany przez program ”Syntezator”. Sampl przenoszony zostaje do panelu ”nagrane sample w bazie językowej” Rys. 2.2. Podświetlenie sampla w panelu ”nagrane sample w bazie językowej” i klikniecie ikony głośnika, powoduje jego odtworzenie, natomiast zielona ikona służy do usuwania odpowiednika dźwiękowego i przeniesienia wzorca znakowego na ”listę sampli do nagrania”.
Obsługa mikrofonu została zrealizowana przy pomocy specjalnie napisanej do tego celu biblioteki. Sample zapisywane są w formacie WAVE. Struktura typu WAVEFORMATEX na potrzeby funkcji ”waveInOpen” została wypełniona jak na podanym poniżej przykładzie.
W celu zmiany jakości dźwięku sampli trzeba zmienić powyższe parametry struktury.
II.3 Analizator struktur
Analizator struktur jest aplikacją do edycji struktur językowych, zostały one omówione w rozdziale [1.2], gdzie przedstawiono przykłady ich użycia, oraz budowę. Budowę pojedynczej struktury, z jakich składa się cała tablica struktur przedstawia również ”załącznik 4”.By dodać nową strukturę należy podać ”maskę” (ilość znaków przed lub po ”haśle” oznaczonych symbolem ”#” dla jednego znaku). W przypadku, gdy ”maska” występuje przed ”hasłem” wpisana zostaje w pole (1) oznaczone na Rys. 2.3, analogicznie dla ”maski” po ”haśle” zostaje ona umieszczona w polu (3) Rys. 2.3. ”Efektor” należy podać w polu (4) Rys. 2.3. Struktury proste jak (na przykład ”m.n.p.m”), jakie nie wchodzą w skład struktur złożonych należy nagrać w programie ”Sampler”.
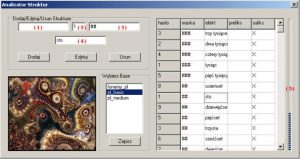
Rys. 2.3 Analizator struktur, program z pakietu ” SYNT”
Baza struktur jest bazą o rozmiarze statycznym (ograniczonym objętościowo). Przeznaczono w niej miejsce na zapisanie maksymalnie stu rekordów. Pasek informujący o poziomie zapełnienia bazy został umieszczony obok wyświetlonych rekordów, oznaczony jako (5) na Rys. 2.3. Po podświetleniu wybranej bazy z danymi (panel ”Wybierz bazę”) istnieje możliwość dodawania i usuwania zasad struktury (panel ”Dodaj/Edytuj/Usuń struktury” Rys. 2.3) klikając przycisk ”Dodaj”, lub ”Usuń” (po ich uprzednim wybraniu z wyświetlonych rekordów). Wszystkie zmiany dokonane podczas edycji wybranej bazy językowej, zostają zapisane po kliknięciu w przycisk ”Zapisz” (panel ”Wybierz bazę” Rys. 2.3).
II.4 Syntezator
Syntezator jest głównym programem pakietu ”SYNT” z punktu widzenia użytkowego. Wykorzystuje on wszystkie zbudowane we wcześniej omówionych programach elementy języka. Efektem działania TTS jest mowa werbalna odtwarzana przy użyciu karty dźwiękowej komputera lub modemu. Przed rozpoczęciem pracy w programie należy wczytać bazę sampli wybrając ją z rozwijalnej listy oznaczonej jako (4) na Rys. 2.4. Program wyposażony jest w opcję odczytu plików tekstowych zapisanych na dysku twardym, lub też na innym nośniku.
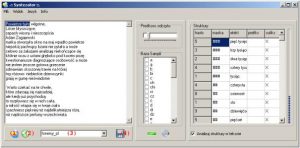
Rys. 2.4 Syntezator mowy, z pakietu ”SYNT”
Po wybraniu w menu ”Plik” i ”Otwórz z pliku” należy wskazać tekst w formacie *.txt i go wczytać. W trakcie działania programu istnieje możliwość wysłania komunikatów do odczytu z innych aplikacji. Tryb ten wiąże się z ciągłą pracą programu, by nie przeszkadzał on w wykonywaniu innych operacji, aplikacja po zminimalizowaniu znajduje się obok zegarka (pośród takich ikon jak połączenie sieciowe, regulacja głośności itp.), tak zwany pasek ”tray”. Odczyt tekstu, jaki nie został wysłany z innej aplikacji, następuje po kliknięciu ikony oznaczonej jako (1) na Rys. 2.4. Sąsiadująca ikona (2) przedstawiona na Rys. 2.4 czyści pole tekstu do odczytu. Syntezator został wyposażony w dwa tryby obsługi; ”prosty” i ”zaawansowany”. Przełączenia można dokonać w menu ”Widok”. Różnią się one nie tylko wielkością okna syntezatora, ale i możliwościami podglądu struktur językowych, bazy sampli, i prędkości odczytu. Tryb ”zaawansowany” daje możliwość odsłuchania pojedynczych sampli a nawet ich czasowego usunięcia. Ustawienia syntezatora zapisywane są automatycznie po jego wyłączeniu. Przy ponownym uruchomieniu otworzy się on w takim trybie, w jakim został zamknięty. Ustawienia dotyczące bazy danych językowych jak na przykład prędkość odczytu sampli, można zapisać klikając ikonę ”dyskietki” (4) pokazaną na Rys. 2.4. Ustawienia te zostaną wczytane przy ponownym otworzeniu bazy językowej.
Odnośniki
- Pakiet SYNT – skompilowane programy do pobrania z repozytorium
- Pełen tekst w formacie PDF